hashMap的那些事
JDK7的HashMap
HashMap是非线程安全的。高并发下会发生死循环(注意:不是死锁)。
工作原理
HashMap的数据结构基于数组和链表。用数组存储HashMapEntry元素。
put时,调用hashcode计算出key的hash值从而得到bucket位置。如果该坐标下已经有值,发生碰撞,通过链表将产生碰撞冲突的元素组织起来。在Java 8中,如果一个bucket中碰撞冲突的元素超过某个限制(默认是8),则使用红黑树来替换链表,从而提高速度。
get时,我们将K传给get,它调用hashCode计算hash从而得到bucket位置,并进一步调用equals()方法确定键值对。
如果数组的长度很短,那么冲突就会很多。所以,插入后会计算是否>=阈值threshold,是,则增大数组长度。此时所有的元素重新再存一次,这叫rehash,成本很高。(HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。)
源码分析问题
转载:https://coolshell.cn/articles/9606.html
以下是put源码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
| public V put(K key, V value) { ...... int hash = hash(key.hashCode()); int i = indexFor(hash, table.length); for (Entry<K,V> e = table[i]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { V oldValue = e.value; e.value = value; e.recordAccess(this); return oldValue; } } modCount++; addEntry(hash, key, value, i); return null; }
|
增加一个节点。
1 2 3 4 5 6 7 8
| void addEntry(int hash, K key, V value, int bucketIndex) { Entry<K,V> e = table[bucketIndex]; table[bucketIndex] = new Entry<K,V>(hash, key, value, e); if (size++ >= threshold) resize(2 * table.length); }
|
新建一个更大尺寸的hash表,然后把数据从老的Hash表中迁移到新的Hash表中。
1 2 3 4 5 6 7 8 9 10 11 12
| void resize(int newCapacity) { Entry[] oldTable = table; int oldCapacity = oldTable.length; ...... Entry[] newTable = new Entry[newCapacity]; transfer(newTable); table = newTable; threshold = (int)(newCapacity * loadFactor); }
|
迁移。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22
| void transfer(Entry[] newTable) { Entry[] src = table; int newCapacity = newTable.length; for (int j = 0; j < src.length; j++) { Entry<K,V> e = src[j]; if (e != null) { src[j] = null; do { Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next; } while (e != null); } } }
|
多线程put时元素丢失
addEntry方法的(1)处,table[bucketIndex] = new Entry(hash, key, value, e); 两个线程都获得了e,他们的next都指向e,之后给相同的位置赋值,必然一个覆盖一个,最终丢失一个。
rehash可能导致死循环
正常下rehash
假设hash算法就是简单的用key mod 一下表的大小(也就是数组的长度)
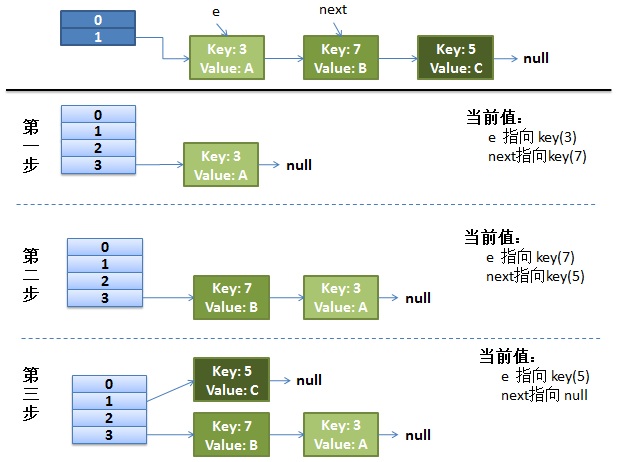
并发下rehash
1 2 3 4 5
| Entry<K,V> next = e.next; int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; newTable[i] = e; e = next;
|
两个线程,线程1走到(1)处暂停。线程2执行完毕了。
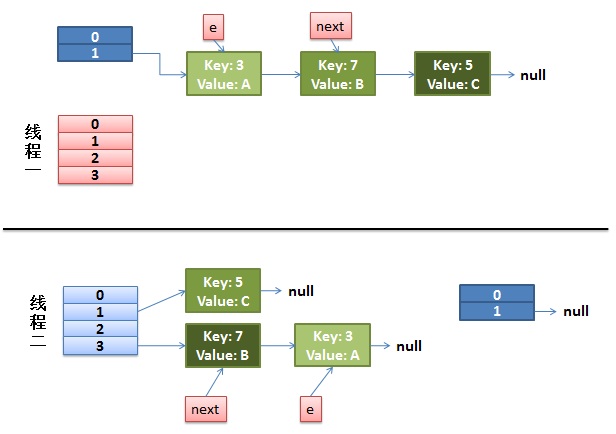
之后,线程1又开始执行。
走到(2)处,e的next就指向了(key:7),走到(3)处,此时,数组3的位置就形成了一个带环链表。当get()的时候,就会陷入死循环,cpu会上升。
e、next虽然是线程私有,但是它们之前已经指向了共有的table中的entry。所以即使线程二将table中entry换了地方,但是entry本身并没有变,只是本身的存储位置或者其next指向发生变化,e和next还是指向原来的entry。所以当e和next继续执行时,还是指向原来的entry,但是原来的entry的位置和指向已经变了。从而导致线程一继续执行时,又将原来的entry的指向和位置再次发生变化,最终导致环。
解决办法
1、hashtable或Collections.synchronizedMap。( synchronized 同步锁,严重牺牲了性能,而且对并发的效率就更低了)
2、ConcurrentHashMap替换HashMap(通过复杂的策略不仅保证了多线程的安全又提高的并发时的效率)
JDK8-HashMap
Java8的HashMap的数据结构,跟之前版本不一样的是当table达到一定的阀值时,bucket就会由链表转换为红黑树的方式进行存储。
探索HashMap实现原理及其在jdk8数据结构的改进
ConcurrentHashMap
https://my.oschina.net/zhupanxin/blog/269037
深入分析ConcurrentHashMap
LinkedHashMap
http://blog.csdn.net/justloveyou_/article/details/71713781